Remember back when every sci-fi book, TV series and film had a computer that could be operated by voice? The hero simply speaks, and the computer answers (though, it doesn’t always give the answer the hero is looking for…). Well, the future is here — and there’s much more to it than you probably thought when you were a kid.
Why voice control matters
Well, if it were only a fancy feature, nobody would actually implement it — there are so many more useful things you can do with your developers’ time (and your app budget) than building features that don’t benefit the final user. However, voice control is really important for the following reasons:
- Accessibility. When building apps, you should always keep in mind that not all users will have perfect vision. Voice control makes operating the app easier for users with visual impairments.
- Safety. A hands-free interface is a huge convenience e.g. while driving a car or performing any other task that requires both hands and a high level of concentration. With the help of voice control, your app can be operated by more users at any time.
Sounds like something you wish your users had? There’s one more way to use voice control:
- Interaction. When building machines such as robots and moving vehicles, speech-recognition enables the user to communicate and control the devices easily. This is a very specific case of voice control implementation. To help you familiarise yourself with the topic, I’ll introduce you to the whole process.
How to make a computer understand you
First of all, you need to understand the difference between speech recognition andnatural language processing.
Speech recognition converts spoken word to written text. Using a speech-to-text (STT) engine, you can dictate messages or emails to your device and then send them. You can also use text-to-speech (TTS) techniques to imitate the voice. For example, with Google Translate’s TTS you can check how a word is supposed to sound.
Natural Language Processing is a much more advanced field of computer science that is concerned with understanding the meaning of the user’s phrase. It uses artificial intelligence and machine learning to catch what you actually meant when you spoke to the device.
If you want your app to let the user order a pizza or book tickets on the next flight to Hawaii, it needs a natural language processing engine. The app can only help you when it understands the true meaning of your request. It should not only HEAR you, but alsoUNDERSTAND you.
Research requirements
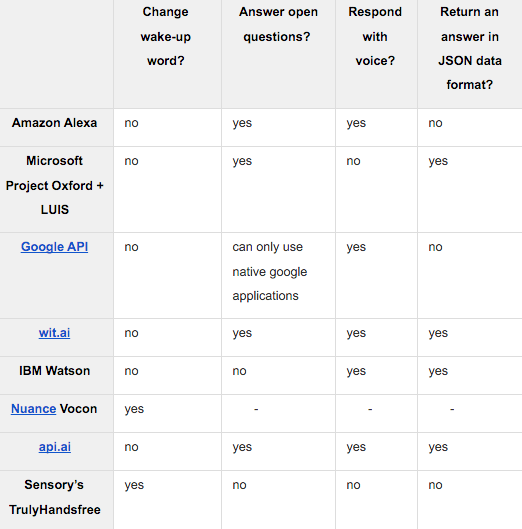
Let’s assume that our goal is to create a personal assistant mobile application called Lucy (“à la Siri”). We’ve defined the requirements we need to achieve for the best user experience. The app needs to have the ability to:
- set a wake-up word (“Lucy”). The ideal solution should have a built-in feature for setting a custom keyword, which allows us to leave the push-to-talk button behind.
- answer open questions. This feature is connected to the application’s ability to recognize natural speech and respond to the request with an action.
- return a voice answer. The ideal solution should have a built-in “text-to-speech” engine. It should return an out-loud answer to questions and requests.
- return JSON code. This code could be used later to communicate with other applications.
We’ve compared the following technologies: PocketSphinx, Project Oxford (Microsoft), Alexa (Amazon), Google Voice Interaction, wit.ai, api.ai, IBM Watson, Nuance, and Sensory.
PocketSphinx
The most difficult issue mentioned above is the first one: setting a custom wake-up word. We don’t want to use a cloud service for this feature because continuous connection with the Internet will negatively affect battery life. Instead of cloud services, we use PocketSphinx– an open source solution for Android.
We are using PocketSphinx as an offline solution only for keyword recognition. Later, we’ll require some cloud service to handle the request.
Pros:
- With Sphinx it is possible to set a custom wake-up word.
- Sphinx works offline (lower battery consumption).
Cons:
- PocketSphinx is not accurate enough to get the effect we want to achieve. It reacts not only to the “Lucy” wake-up word.
- There is a pause after Sphinx recognizes a keyword and launches the cloud service.
Project Oxford (Microsoft)
Project Oxford is a speech-to-text engine from Microsoft. It works well enough, but we need to implement additional API’s to achieve the desired functionality.
Pros:
- Powerful in combination with LUIS (Language Understanding Intelligent Service) andCRIS (Custom Recognition Intelligent Service).
Cons:
- At the moment, we have a beta version of LUIS and CRIS, and we do not recommend using beta versions for commercial products due to stability concerns.
- We have to manually implement intents.
Alexa
Alexa Voice Service (AVS) is a cloud speech-recognition service from Amazon. It is used in Amazon’s Echo. Here’s how it works:
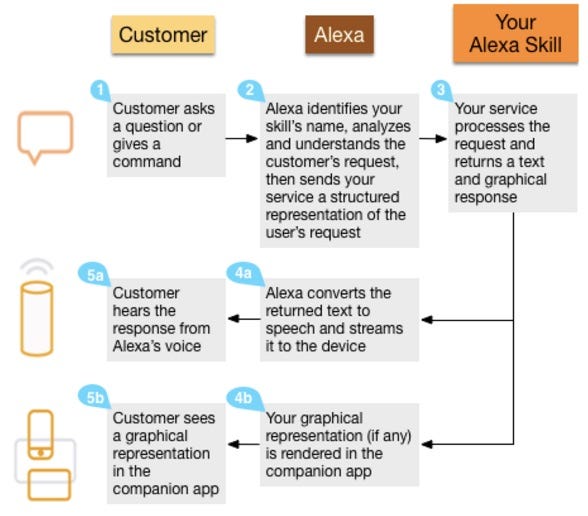
“Alexa” is the wake-up word and starts the conversation. Our service gets called when customers use our invocation name, such as: “Alexa, ask Lucy to say hello world.” This example is a simple command-oriented one. ASK also supports more sophisticated multi-command dialogues and parameter passing. The above example would work like this:
- “Alexa” is the wake word that starts the conversation.
- “Ask…to” is one of the supported phrases for requesting a service.
- “Lucy” is the invocation name that identifies the skill we want (in our case it’s the name of our app).
- “Say hello world” is the specific request, question, or command.
Pros
- Alexa provides a set of built-in skills and capabilities available for use. Examples of built-in Alexa skills include the ability to answer general knowledge questions, get the current time, provide weather forecast information and query Wikipedia, among others.
- Returns an mp3 with an answer.
Cons
- To get custom intents within AVS it is necessary to create, register and test them with the Alexa Skill Kit.
- Complicated documentation.
- To capture the user’s utterances, the device needs to have a button to activate the microphone (push-to-talk). We’ve contacted Amazon and got information that far-field voice recognition or using a spoken word to trigger activation of the Alexa Voice Service is currently unavailable.
Google Voice Interaction API
This API works in a similar way to Alexa. Google Voice Actions recognizes many spoken and typed action requests and creates Android intents for them. Apps like Play Music and Keep can receive these intents and perform the requested action. Our app can support some of these actions too:
- Define an intent filter.
- Handle the intent in the app.
- Update the completion status of your app.
Unfortunately, with this solution we are not able to change the “OK, Google” wake-up word. The Google API is insufficient for us, as it only allows us to handle intents:
- User says ‘ok, google’
- Android will open its default search engine
- The user speaks a keyphrase that is matched to our app’s intents
- It will launch the application and handle the intent.
Wit.ai
How wit.ai works:
- Provide a sentence we want the app to understand. Then either select an existing intent from the Community or create our own.
- Send text or stream audio to the API. Wit.ai gets structured information in return.
- Wit.ai learns from usage and helps improve configurations.
Pros:
- Returns JSON.
- Already has a large number of built-in intents.
- Ability to learn from the user.
Cons:
- Not stable enough. During the test it was shut down after 30 sec.
- Not so comfortable to use.
Api.ai
The Api.ai platform lets developers seamlessly integrate intelligent voice command systems into their products to create consumer-friendly voice-enabled user interfaces. We made a test application using Api.ai and it was closest in quality to Amazon Echo.
Pros:
- Easy to implement, clear documentation.
- Ability to learn and adapt (machine learning).
- Complete cloud solution (only without keyword activation): Voice recognition + natural language understanding + text-to-speech.
- Returns a voice answer.
- User friendly.
Cons:
- It has only push-to-talk input.
IBM Watson
IBM Watson is a powerful tool for machine learning and analytics. Basically, it focuses on analyzing and structuring data and has speech-to-text and text-to-speech solutions. It is good for big data analysis but it doesn’t fit the purpose of our application.
Nuance
Nuance provides many voice recognition and natural language processing services. It has a ready solution for mobile speech-recognition: VoCon Hybrid, which could solve our most difficult issue — custom keyword recognition.
Pros:
- Always-listening mode with keyword activation removes the need for a push-to-talk button — a key advantage of this technology.
- All-inclusive main menu (a1M). Enables all commands to be spoken in a single utterance on the main menu. We want a similar interface.
Cons:
- Closed technology. It is not an open source API — if you want to use it in your project you need to contact Nuance and ask for samples to test it.
- Complicated documentation and set-up. We got the sample of this solution to test and we were unable to launch it and make it work. This solution requires additional time for testing.
Sensory
Sensory is another expert in the speech-recognition field. TrulyHandsfree is one of the solutions they offer and it looks promising. It is a good alternative to PocketSphinx and we recommend it if you want a high quality application. Unfortunately, it’s not free.
Pros:
- Always-listening mode. With TrulyHandsfree you can set up a custom wake up word.
- High accuracy. The technology can respond to commands delivered from as far as 20 feet away or in high noise conditions.
- Ability to include pre-built commands. This is a great feature, you can set predefined commands and there’s no need for an Internet connection to handle them.
Cons:
- Closed solution. If you want to set a custom keyword, like “Lucy”, you need to contact Sensory.
- This solution solves only our first issue. It does not include a natural language processing engine and requires other services to handle complicated requests.
Functionality comparison
Conclusions
To sum up, we found the following:
- The Google Voice Interaction API and Alexa Voice Service provide similar functionality. It is possible to launch an application and make an intent through their systems but it’s impossible to customize it in the way we want. With these services, users will communicate mainly with Google and Alexa and not with our application. We believe that it is better not to use these solutions as they don’t allow us to build a strict connection with the application as an independent product.
- Api.ai and wit.ai work in a similar way; they solve open questions and can return JSON code. We did tests and made a demo application and decided that Api.ai is better as it is more user friendly, works smoothly and provides us with ready solutions for voice recognition (text-to-speech), natural language processing and text-to-speech. We built a test application and obtained appropriate speech-recognition functionality. Unfortunately, Api.ai only uses a “push-to-talk” approach.
- Nuance provides a ready solution — VoCon Hybrid. The main advantage of this technology is that it has an always-listening mode and the ability to set up a custom wake-up word. It also has numerous advantages, such as:
- An all-inclusive main menu (Enables all commands to be spoken in a single utterance on the main menu).
- Multi-lingual and partial phonebook name selection (Recognizes partial contact names for multi-lingual phonebooks).
- Natural language understanding (Recognizes natural speech, eliminating the restriction to predefined commands for all VoCon Hybrid languages).
However, Nuance technology is not available for free usage, and if we want to use it in the project it is obligatory to contact them.
- Sensory’s TrulyHandsfree is a great alternative to PocketSphinx, but it is also not free and fulfills only one item on the list of requirements.
Our recommendations
- At this point, api.ai has the best result in tests and we would recommend its use as a cloud service for voice recognition and natural language processing. One of the biggest advantages of this service is that it is a ready to use product, unlike the other cloud services. Api.ai allows us to use an easily integrated solution.
- Api.ai, like the rest of the cloud services, does not solve the wake-up word issue. At this point, we see the following options:
- Use Sphinx as an offline solution, and make efforts to get it working as well as possible + api.ai for speech-recognition.
- VoCon Hybrid from Nuance — as a ready solution for wake-up word + api.ai for natural language processing (answering open questions and returning voice answers)
- Use Sensory’s TrulyHandsfree for wake-up word recognition + api.ai
- Use a hardware solution for keyword detection. Implementation of a hardware solution could increase the quality of wake-up word detection, then we could useapi.ai.
We hope this article gives you a comprehensive introduction to the speech-recognition and natural language processing solutions available at the moment. If you have any questions, doubts or suggestions — don’t hesitate to leave a comment!
Check out this article on our site and find a lot more information about web development.